Benefit of Federated Learning in Biomedical Image Segmentation
Written by Neil Botelho, Gaurang Govekar & Vivek Silimkhan
This is a summary of the work we’ve done during our 1 month internship at Persistent Systems Ltd. We would like to thank Amogh Tarcar and Penjo Rebelo for giving us this opportunity and guiding us throughout the internship.
In this article we’ll explain our experiments showing clear benefits to using federated learning when training on sensitive/private data like in hospitals.
What is federated learning ?

In traditional machine learning, you train a single model on a single set of data. In federated learning, you train multiple models(called parties), each one with their own private data, then the weights of these models are collected by a central server(called the aggregator).
The aggregator, uses a predecided algorithm to average/fuse the weights of all the models, and sends the resulting weights back to the parties.
The parties then update their models with the aggregator weights and continue training. This process of local training(at the party side), global aggregation and updating the local model, is called a global round.
But why use federated learning ?
Federated learning allows us to train on sensitive datasets without risking the privacy of participants. One famous example of this is the training of Gboard, Google’s keyboard for Android. Rather than sending the keyboard usage data of each user to a central server, Google trained their model locally on each users device and sent only the weights of the model to the central server. Hence there was no risk to the users data.
Another big use of federated learning is in hospital data. Machine learning and artificial intelligence has shown a lot of progress in the fields of oncology, pathology, radiology, etc. But the main issue with training such models on a large scale is that health care data is very sensitive. So each hospital is limited to the data they have acquired from their own patients and it’s hard to accumulate a sizeable dataset to train a model.
This problem can easily be solved with the use of federated learning. A group of hospitals can come together to implement federated learning, where each hospital can act as a party. One of them can host the aggregator or they can choose a trusted third party to be the aggregator.

In this setting, the data does not have to be shared amongst the hospitals, even the aggregator will not have access to data from each hospital. The models, or more specifically the weights of the models of each party will be aggregated and only the aggregated model is shared across the group. Which means each hospital will get a model that has insights from a much larger dataset than what they had from just their own patients.
The Fusion Algorithm
The algorithm that the aggregator uses to aggregate the weights of the parties is known as the fusion algorithm. There are several fusion algorithms to choose from like FedSGD and Iterative Average. But the usual choice of fusion algorithm is the FedAvg algorithm. In the FedAvg algorithm, all parties have the same model after an aggregation step, i.e. after the model weights are aggregated and sent to the parties, the parties overwrite their own model weights with that of the global aggregated model.
But if the data held by one of the parties is vastly different to that of the other parties, then forcing all the parties to try to produce a common model could cause the training of all models to suffer.
To solve this problem we use the Fed+ family of fusion algorithms. The main idea behind Fed+ is that parties don’t have to produce the same model. Each party can train more on its own data and simultaneously gain some insights from other parties data. Rather than overwriting the local model with the weights of the aggregated global model, we take a mix of the global and local model weights according to the formula.
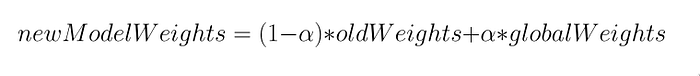
The parameter alpha decides the importance of the global and local models. If alpha was 1, we would just overwrite the local model weights with the global model weights and if alpha was 0, we would simply reject the global model weights entirely.
The Segmentation Task
The task we chose to train a model on was segmentation of polyps in images of the gastrointestinal tract. Image segmentation is essentially separating out a particular object or a group of objects in an image by filling the object with a particular colour to separate it from the background.

Like most computer vision problems, for building image segmentation models a large amount of data is necessary. But to get the image mask (an example of which can be seen on the right of the above image) for training the model, a person needs to identify the object of interest and manually select the pixels that make up the mask.
This task is even harder when it comes to medical image data. With respect to polyp images, it is often challenging for a person to detect polyps visually in images of the GI tract, as they are often hard to differentiate from surrounding normal tissue. This is especially true for the small, flat, and sessile polyps that are typically not visible during colonoscopy.
Additionally the laws around privacy of medical data make it hard to share data between different medical organisations. Therefore it is difficult to find large datasets of annotated medical images with corresponding segmentation masks.
Datasets Used
In our experiments we used 2 separate datasets of segmented images of the GI tract, namely
1)The Kvasir-SEG Dataset
2) The CVC -ClinicDB segmentation dataset
The Kvasir dataset consists of images collected and verified by experienced gastroenterologists from Norway. The CVC dataset consists of images collected from Spain.
The idea behind using these datasets from 2 different countries, is to simulate how datasets from different medical organisations would have overarching differences. They may use different brands of imaging equipment, the people from the 2 countries would presumably have different average GI tract “healthiness” etc.
Experiment setup
We used IBM’s Federated learning library, as it provides prebuilt classes for federated training, and has support for various Fusion algorithms.
Since we were performing segmentation, accuracy doesn’t work as a metric. This is because even if the model just predicted the entire image as black when the masked area was white, the accuracy would still be over 80%. This is because in the polyp images, the masked areas are usually a very small part of the image. Therefore we used PSNR(Peak Signal to Noise Ratio) and SSIM(Structural Similarity Index Measure) as metrics.
We trained a central model on 80% of the CVC clinic data, the remaining 20% was used for validation. Training continued until the validation PSNR score either decreased or remained stagnant for many epochs. We took this to indicate that the model could not improve further even if trained for more epochs
This model was saved and loaded into 2 parties we will call party A and party B. Party A was given 600 datapoints from the Kvasir-SEG dataset, and party B was given the same 80% of the CVC clinic data as the central model. We trained the models in a federated setting using soft updates, with alpha set to 0.5 for both models
Results
The central model had a maximum validation PSNR of 16.5 and a maximum validation SSIM score of 0.75.

The federated party training on CVC data got a max validation PSNR of 18.4 and a maximum validation SSIM score of 0.92

We can see that there is a clear benefit from training the segmentation model in a federated setting. Despite not being able to improve further in the central model, the CVC party in the federated setting showed clear improvement.
This means that the central model could not learn further from just the CVC data. But in the federated setting the CVC party’s model improved because it learned from data belonging to the Kvasir party without having to share data between the parties.
This shows how various parties can pool their data to train a model to gain the benefit of a larger dataset without actually sharing their data.
Conclusion
It would be very difficult to gain access to a diverse variety of medical data if we use traditional central machine learning since we would need to collect different hospital’s and medical organisation’s sensitive patient data into a single place. But with federated learning no 3rd party ever sees the data so medical organisations would be more willing to share their data.
With traditional machine learning, models are forced to learn from a single limited source of data to accommodate various constraints regarding the privacy of individuals data. Federated learning brings a promising way to advance the field of machine learning by enabling us to collectively learn from several sources of data, without risking the privacy of the datasets.
References
[1] Sheller, M. J. et al., Multi-institutional deep learning modeling without sharing patient data: a feasibility study on brain tumor segmentation.
[2] IBM Federated Learning: An Enterprise FrameworkWhite Paper V0.1
[3] Trustworthy federated data analytics (2020)
[4] The federated tumor segmentation (fets) initiative (2020)
[5] McMahan et al., Communication-Efficient Learning of Deep Networksfrom Decentralized Data (2017)
[6] Saruar Alam et al., Automatic Polyp Segmentation using U-Net-ResNet50
[7] Yu et al. , Fed+: A Family of Fusion Algorithms for Federated Learning (2020)
[8] Lee J, Sun J, Wang F, Wang S, Jun CH, Jiang X. Privacy-Preserving Patient Similarity Learning in a Federated Environment: Development and Analysis. JMIR Med Inform.(2018)
